How to install Foundry Local and start running Local AI Models easily!
Start running Local AI easily with Microsoft Foundry Local!

Microsoft released a lot of interesting stuff at Build 2025 this week, of course a lot of them focused around AI - who would have thought! 😆
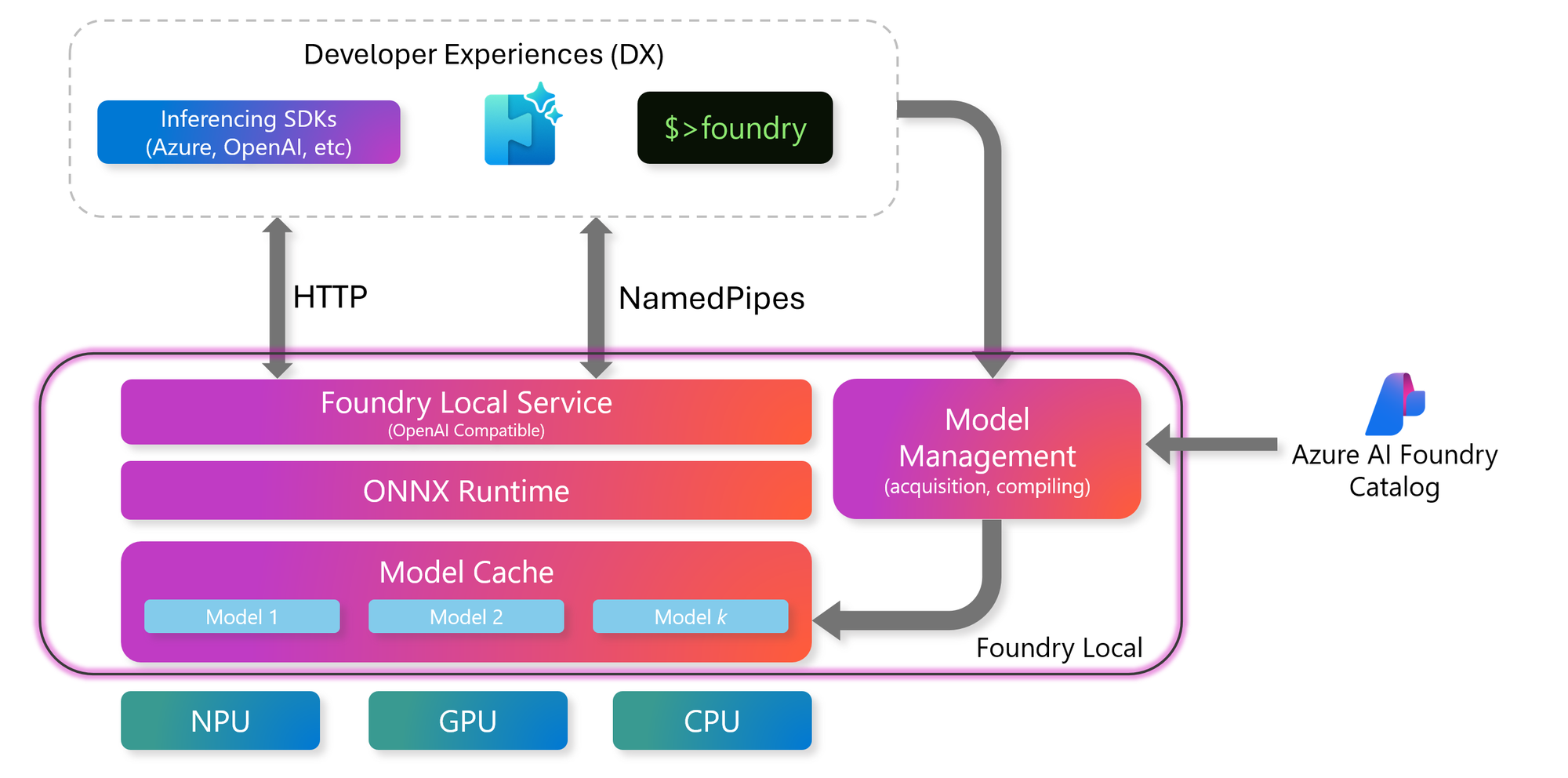
However one thing that really caught my eye was the introduction of Foundry Local, which offers an easy platform for On-Device AI Inference. What that actually means is: Running AI Models locally on your own hardware. What really interested me here is the simplicity of the platform and also it's possibilities to scale in the future. Let's go through it's basic features and how to utilize it, after which we can talk about it's potential in the future.
How to install Foundry Local
Getting started and installing Foundry Local is as easy as it can get. Just open up a terminal and install it using WinGet (or brew if you're on MacOS).
After this you can easily list the available models with "foundry model list"
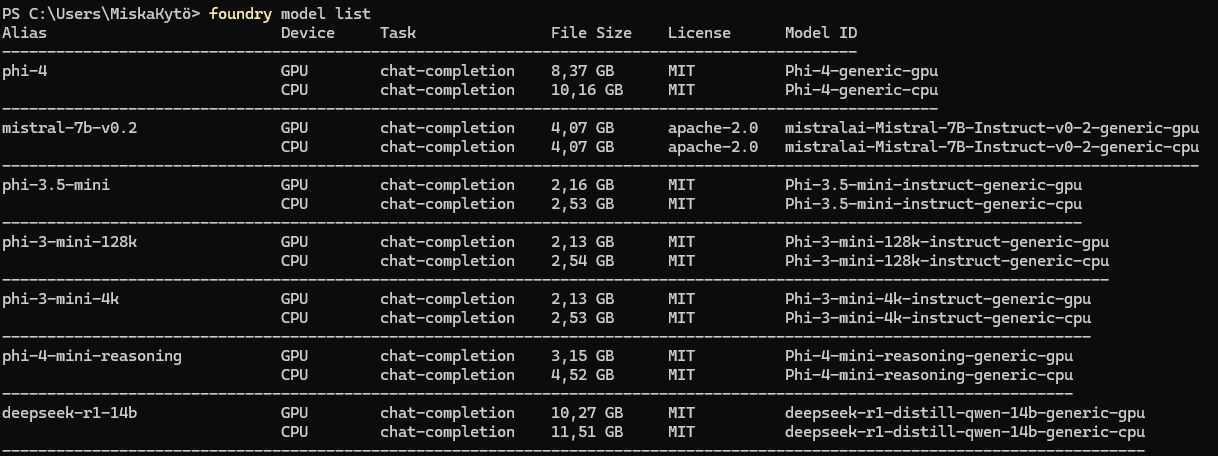
The great thing about Foundry Local is that you don't need to figure out which version of the model would be best for your hardware! You just tell it the model you want to run, after which it installs the best version for you that supports the right acceleration (GPU if you have one, NPU if available, if no acceleration is available, it installs the CPU version).
You can easily try it out by running "foundry model run phi-3.5-mini", and see it download the model and drop you into an interactive chat with the LLM. How easy is that!
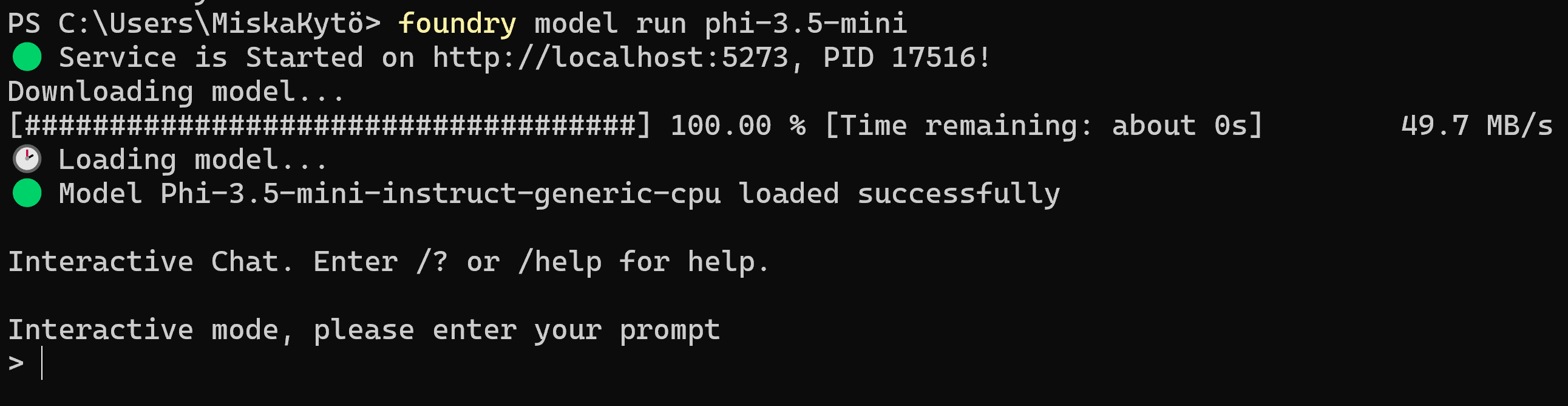
Integrating into Open WebUI or LangChain
Foundry Local is created to be easily integrated into existing AI workloads as a drop-in feature. You can use already existing products like Open WebUI to get a better chat experience for your local AI. You can find the port for your Foundry Local service by running "foundry service status".

Now you just have to add the Foundry Local endpoint to the settings in Open WebUI, and you can start chatting with the models you've downloaded.
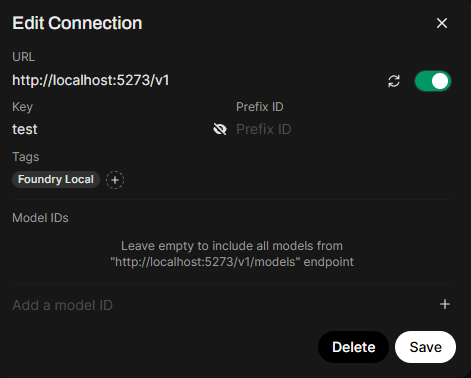
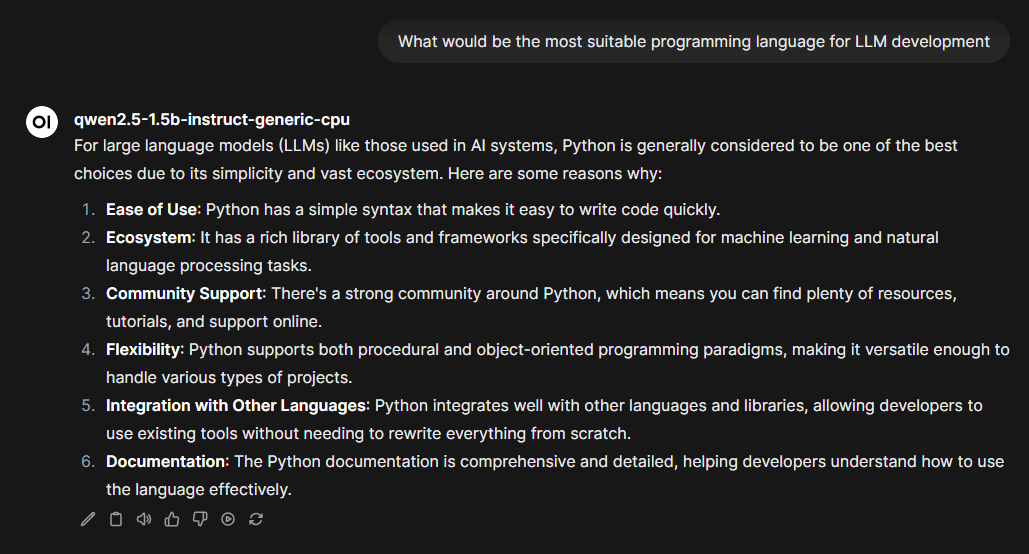
You can also integrate Foundry Local easily into Langchain and your existing AI applications in Python or JavaScript. The Foundry Local SDK is a great way to start utilizing local AI processing in your projects or applications. This makes it easier to create more platform-agnostic local AI projects. The use of model alias' work well here, where you as a developer only define the model you want the program to use, and Foundry Local installs the right accelerated version for each user and their device.
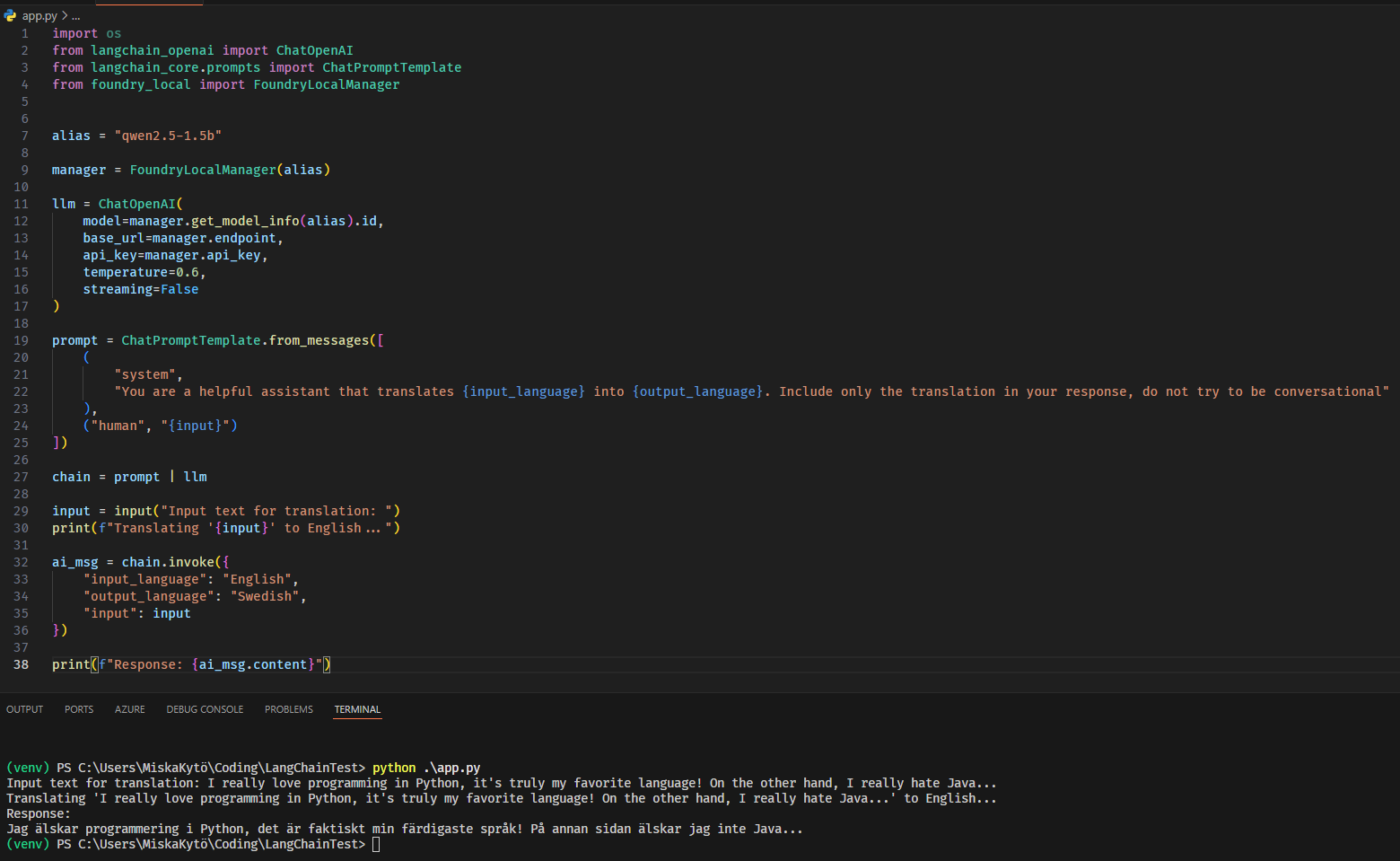
Foundry Local vs Ollama, which one should you use?
When you look through Foundry Local, it clearly is trying to target many of the same users as Ollama already has. And rightfully so, Ollama already has a great community around it, but here are some points where I think Foundry Local can take the lead:
- Foundry Local runs on ONNX (Open Neural Network Exchange), which is an open standard for machine learning and AI workloads. Ollama runs on llama.cpp, which is good but can sometimes be slower than ONNX runtime.
- Ease of setup. Even though Ollama has become quite easy to set up, Foundry Local really shines in how simple it is to setup, without knowing all of the technical things around LLMs and acceleration.
- Easily adapted to already existing projects. Foundry Local can seemingly be easier introduced to already existing products, where they could start offloading some smaller processing from cloud to the local device, especially now that NPUs are becoming more readily available.
Future Potential of Foundry Local
What I really see as one of the main selling points for Foundry Local and Local AI Inferencing in general is something that Microsoft already suggests and hints at in their documentation: Seamless scaling and offloading of AI Inferencing resources between Local and Cloud endpoints.
The main idea is that in the future, organizations can start running AI workloads in the cloud (Azure AI Foundry), and in cases where it makes sense (Low latency requirements, no internet connectivity or very sensitive data) start offloading and moving to processing on the local device. This is becoming more and more viable all the time, since NPUs and GPUs are becoming more powerful and available with newer models of laptops and desktops alike.
You could of course also start on-device and scale into using Azure resources in the cloud, when your workloads need more processing power than what's available on your laptop or desktop.
I could see Foundry Local scaling from "local laptop AI" into more specific AI Inferencing clusters working as Edge Compute, where organizations could run high-availability or confidential AI Workloads, while their other resources run in Azure. It's quite funny to think about, but I think local AI computing might bring on-premises servers back, at least in some capacity. The cloud is good and all, but in this case, local compute resources might actually make sense for some companies.
I really encourage you to check out and play around with Foundry Local, since it's so easy. I am also interested to see where the development of this platform goes, since it was only released to the public this week in Preview! There's still a long way to go, but this is a quite resounding starting point 👀